
들어가며
프론트엔드 기술면접 질문에 단골처럼 등장하는 질문 중 하나가 ‘싱글 스레드인 자바스크립트가 어떻게 비동기 처리가 가능한가요?’이다. 이 질문에 대한 간단한 답으로 ‘자바스크립트를 실행하는 런타임 환경이 비동기 작업들을 담당한다’라던지, ‘비동기 작업의 콜백함수를 별도의 태스크 큐에 저장해놓고, 이벤트 루프가 콜 스택이 비었을 때 태스크 큐의 작업을 콜 스택에 올려서 실행시킨다’라고 말할 수 있을 것이다. 하지만 몇 가지 궁금한 것들이 생겼다.
- 자바스크립트는 애초에 왜 싱글 스레드로 동작하도록 만들어져서 이벤트 루프라는 매커니즘을 써가면서 비동기 처리를 하는 걸까?
- 이벤트 루프와 작업 큐는 그러면 아키텍쳐상 어디에, 어떤 형태로 존재하는 것일까? 흔히 볼 수 있는 그림상으로는 엔진 바깥에 위치하는 것 같은데, 그렇다면 브라우저나 Node.js 시스템 어딘가에 위치하고 있는 걸까?
- 브라우저와 Node.js에서 이벤트 루프가 동작하는 과정에는 어떤 차이점들이 있을까?
- 이벤트 루프의 동작 과정을 이해하는 것이 자바스크립트 개발자에게 왜 중요할까?
{kind=link}
이 질문들에 대한 답을 조금이나마 얻어 보고자 자바스크립트의 실행 모델과 이벤트 루프에 대해 좀 더 자세히 찾아 보았다.
자바스크립트가 싱글 스레드로 동작하는 이유
싱글 스레드 환경에서는 하나의 프로세스에서 한 번에 하나의 작업만 할 수 있다. 반면, 멀티 스레드 환경에서는 하나의 프로세스에서 여러 개의 스레드를 두고 동시에 여러 작업을 할 수 있다. 아래는 Python에서 두 개의 스레드를 생성, 실행하여 하나는 A를 10번, 다른 하나는 B를 10번 출력하게 하는 코드이다.
import threading
import time
def worker(name):
for _ in range(10):
print(name, end="")
time.sleep(0.01)
# 메인 프로그램(프로세스)에서 두 개의 스레드 생성
t1 = threading.Thread(target=worker, args=("A",))
t2 = threading.Thread(target=worker, args=("B",))
t1.start()
t2.start()
# 두 스레드가 끝날 때까지 대기
t1.join()
t2.join()이 코드를 실행시키면 ABBABABABAABABBAABBA 처럼 항상 A, B를 10번씩 출력하긴 하지만 결과값 자체는 매번 다르다.
멀티 스레드 환경에서는 싱글 스레드 환경과 달리 여러 작업을 병렬로 수행할 수 있다는 장점이 있지만, 각 스레드에서 독립된 작업을 수행하기 때문에 메인 프로세스에서 위 예시처럼 결과값을 예측하기 어렵다. 그리고 멀티 스레드 언어로 프로그래밍할 때는 스레드의 실행 도중에 다른 스레드가 개입하여 변수나 객체의 상태를 변경할 수 있다는 점을 주의해야 한다. 다음 C 코드를 보자.
#include <pthread.h>
#include <stdio.h>
int shared_counter = 0;
void* increment_function(void* arg) {
for (int i = 0; i < 100000; i++) {
shared_counter++; // 다른 스레드가 중간에 개입 가능
}
return NULL;
}
int main() {
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, increment_function, NULL);
pthread_create(&thread2, NULL, increment_function, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("최종 카운터: %d\n", shared_counter);
// 예상: 200000, 실제: 불확실 (예: 156789)
return 0;
}위 코드에서 shared_counter++는 한 줄이지만 실제로는 메모리에서 값을 읽고, 1만큼 증가시키고, 증가시킨 값을 메모리에 쓰는 3단계로 이루어지는데, 이 과정에서 다른 스레드가 끼어들면 예상한 결과와 다른 결과를 얻게 된다. 그래서 멀티 스레드 프로그래밍에서는 여러 스레드가 공유 상태(변수, 파일, 메모리 등)에 동시에 접근하면서 이러한 경쟁 상태(race condition)가 발생하지 않도록 조심해야 한다.
다시 자바스크립트로 돌아오자. 자바스크립트라는 언어는 브라우저에서 DOM과 사용자 인터페이스를 조작(manipulate)하여 동적인 웹페이지를 구현하기 위해 등장했다. 다음과 같은 코드를 보자.
document.body.appendChild(element);
element.style.display = 'none';위 코드를 브라우저에서 실행하면 자바스크립트 두 줄이 모두 실행된 후에야 렌더링이 일어나기 때문에 사용자는 element 요소를 볼 수 없다. 하지만 멀티 스레드 환경이었다면 appendChild(element) 실행 후 렌더링 스레드가 개입하여 잠깐 요소가 화면에 보였다가 사라질 수도 있다. DOM 조작의 예측 가능성이 떨어지고 UI 불일치가 발생할 수도 있는 것이다.
이처럼 자바스크립트가 싱글 스레드로 동작하도록 만들어진 것은 DOM 조작을 위해 설계된 만큼 경쟁 상태와 UI 불일치를 피하고, DOM의 예측 가능성을 높이기 위해서라고 볼 수 있다.
자바스크립트는 엔진과 호스트 환경의 협력으로 실행된다
자바스크립트는 동시에 하나의 작업만을 처리할 수 있지만, 실제로 브라우저에서는 애니메이션, 네트워크 요청, 클릭 이벤트 처리 등의 작업이 동시에 처리되고, Node.js 웹 서버에서는 동시에 HTTP 요청을 문제없이 처리할 수 있는 것처럼 보인다. 싱글 스레드라면 이러한 비동기 작업(타이머, 네트워크, I/O, 유저 입력 등)이 완료될 때까지 다른 작업이 중단되어야 한다.
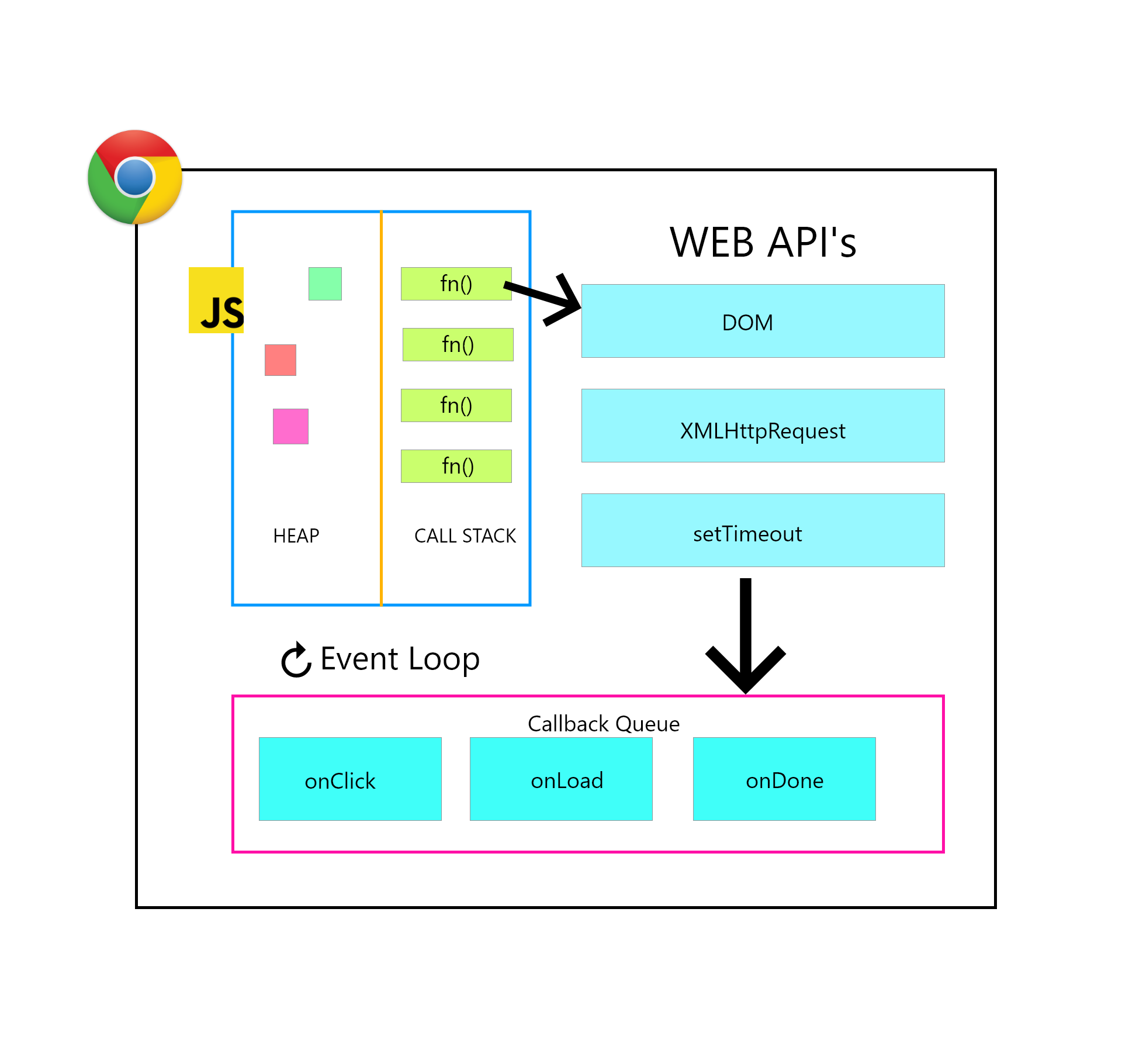
그럼에도 자바스크립트가 동시성(Concurrency)을 지원할 수 있는 것은 자바스크립트의 실행은 싱글 스레드인 자바스크립트 엔진과 멀티 스레드인 호스트 환경(브라우저, Node.js 시스템의 libuv 등)의 협력으로 이루어지기 때문이다.
자바스크립트 엔진(예: V8)은 자바스크립트 코드를 파싱·컴파일하고, 이후에 설명할 단일 콜스택을 사용하여 실행하는 역할만 담당한다. DOM 조작, 네트워크 I/O, 타이머, 파일 시스템 접근 등의 비동기 작업들은 엔진이 구현하고 있지 않고, 엔진 바깥의 호스트 환경이 제공하는 API를 통해 이루어진다. 예를 들어, 크로미움 계열의 브라우저는 메인 스레드 외에도 여러 스레드/프로세스로 나뉘며, 이를 활용해 네트워크, 타이머, 이벤트 등의 작업을 수행하는 Web API를 제공한다.
즉, 자바스크립트 엔진은 단순히 코드의 실행만 담당하고, 실제 비동기 작업을 수행하는 역할은 호스트 환경의 다른 스레드에서 담당하는 것이다. 그리고 이러한 비동기 멀티 스레드 작업들과 싱글 스레드인 자바스크립트 엔진 사이의 상호작용을 담당하는 것이 바로 ‘이벤트 루프’다.
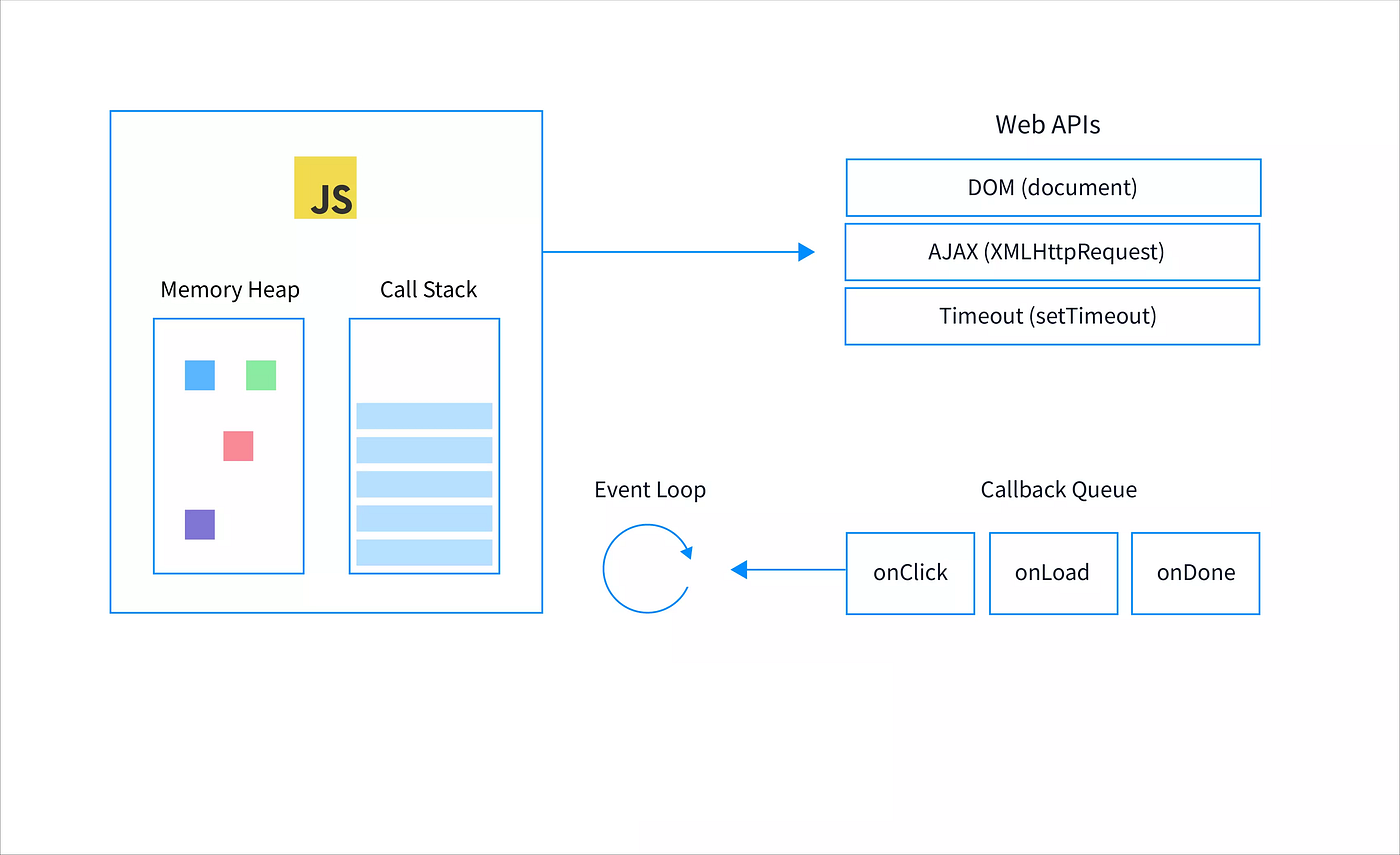
이벤트 루프는 메인 스레드에서의 처리 사이클을 정의한 개념적인 모델일 뿐이다
이벤트 루프는 백그라운드에서 비동기 작업이 완료되면, 그 결과로 실행되어야 하는 콜백 함수를 자바스크립트 엔진의 콜 스택으로 옮겨주는 역할을 한다. 그림으로 봐도 그런 모습이다. 하지만 작업을 ‘옮겨주는’ 모습의 다이어그램 때문에 내가 갖게 된 잘못된 개념이 있다. 바로 엔진에서 한 개의 스레드가 자바스크립트의 실행을 담당하고, 브라우저(또는 Node.js libuv) 어딘가에서 이벤트 루프가 별도의 스레드를 가지고 콜 스택과 작업 큐 사이의 순서를 제어한다고 생각했던 것이다.
{kind=link}
그러나 자바스크립트의 이벤트 루프는 메인 스레드가 콜 스택과 큐를 번갈아 확인하면서 콜백을 실행하는 반복 사이클이 구현된 개념적인 모델일 뿐이다. 그 사이클의 세부적인 정의와 구현이 호스트마다 다를 뿐이고(대표적으로 브라우저와 Node.js에서의 이벤트 루프 동작 원리가 다르다), 이벤트 루프가 엔진 밖 호스트에서 자체적인 메모리나 스레드를 갖고 존재하는 어떠한 ‘실체’는 아니라는 것이다.
그래서 ‘이벤트 루프가 브라우저에 존재하며 자바스크립트의 비동기를 처리한다’는 말은 엄밀히 말하면 반은 틀렸다고 볼 수 있다. 일단 나처럼 브라우저에 실체로서 존재한다고 생각했다면 첫 번째로 틀렸고, 브라우저가 아니라 에이전트(Agent)마다 존재할 수 있기 때문이다.
그럼 에이전트가 뭘까? 이는 MDN에서 설명하는 자바스크립트 실행 모델에서 확인할 수 있다.
자바스크립트 실행 모델
일단 자바스크립트가 실행되는 런타임 환경의 세부적인 구현은 조금씩 다르기 때문에, 여기서 설명하는 자바스크립트 실행 모델은 기본적인 infrastructure를 이론적이고 추상적으로 소개하고 있다.
Agent는 자바스크립트를 싱글 스레드로 실행하는 논리적 실행 단위이다
자바스크립트 스펙에서 에이전트(Agent)는 코드 실행을 담당하는 논리적 주체로, 하나의 실행 흐름(싱글 스레드) 안에서 동작한다. 한 에이전트는 자체 힙(객체 메모리), 스택(콜 스택), 태스크 큐(이벤트 루프)를 가진다. 에이전트는 여러 영역(Realm)을 소유할 수 있으며, 같은 에이전트 내의 영역들은 서로를 동기적으로(싱글 스레드로) 호출할 수 있다.
여기서 영역이란, 자바스크립트가 실행되기 위해 갖추어야 할 요소들이 포함된 전역 실행 환경을 뜻한다. 웹을 예로 들면, Window, WorkerGlobalScope, <iframe> 등은 모두 각자의 고유한 영역을 갖고 그 안에서 아래의 요소들을 가지고 스크립트를 실행하게 된다.
- 전역적으로 선언된 변수, 전역 객체(window, global, WorkerGlobalScope…), 전역 객체를 참조하는 globalThis 값 등
- 내장 고유 객체: Object, Array, Promise 같은 표준 객체의 “복사본”
- 각 영역마다 고유한 프로토타입/생성자를 갖는다고 생각하면 된다. 그래서 A iframe에서 만든 배열을 B iframe에서 검사하면, B의 Array는 A와는 다른 영역의 Array이기 때문에
arr instanceof Array가 false를 반환한다. 그래서 배열 타입인지 검사하고 싶다면Array.isArray()와 같은 메서드를 활용해야 한다
- 각 영역마다 고유한 프로토타입/생성자를 갖는다고 생각하면 된다. 그래서 A iframe에서 만든 배열을 B iframe에서 검사하면, B의 Array는 A와는 다른 영역의 Array이기 때문에
- 호스트별 API: 타이머, DOM, fetch 등 호스트가 제공하는 API
- 모듈/스크립트 코드: 영역에서 로드·컴파일된 자바스크립트 코드와 모듈 그래프
하나의 에이전트는 여러 영역을 소유할 수 있다고 했다. 다르게 말하면 영역은 서로 다르더라도 하나의 에이전트로 묶여서 메모리 힙(Heap)을 공유할 수 있는 경우가 있다는 건데, 대표적으로 브라우저에서 같은 출처의 메인 Window와 iframe은 하나의 “similar-origin window agent”로 묶여서 직접적인 접근이 허용된다. 반면, Web Worker나 Service Worker 등의 Worker 종류들은 각각 별도의 에이전트를 형성하기 때문에 postMessage로 소통해야 한다.
아래 그림을 보면, HTML Page와 Worker는 서로 고유한 에이전트를 가지며 자체적인 메모리 힙과 스택, 작업 큐(이벤트 루프)를 운영하는 것을 볼 수 있다. 그리고 HTML Page 에이전트는 메인 Window와 내부의 iframe 각각의 영역을 소유하고 있으며, 이 영역들은 에이전트의 메모리 힙을 공유하는 것을 볼 수 있다.
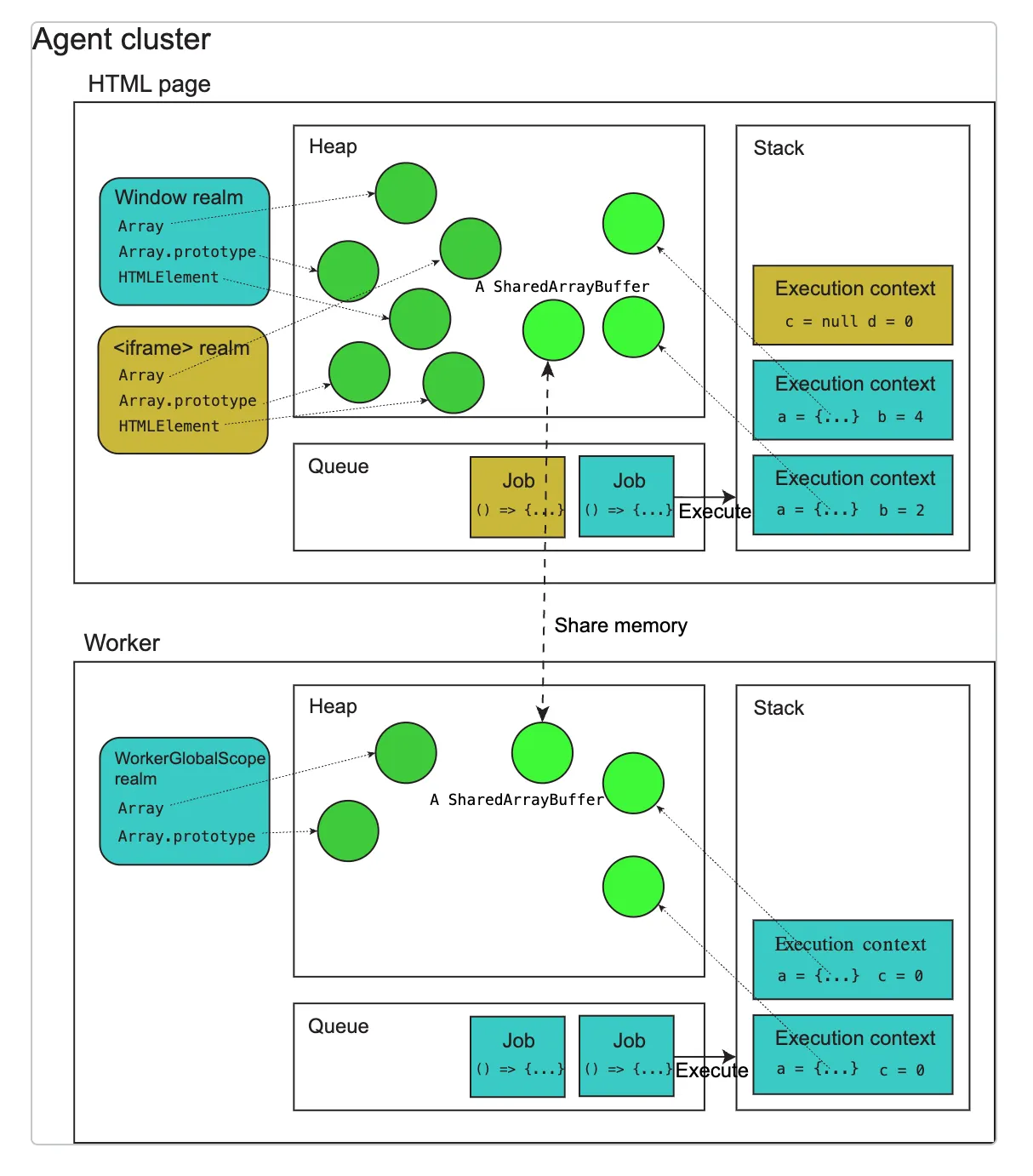
한 가지 더 살펴보면, HTML Page와 Worker 에이전트가 하나의 Cluster로 묶여서 공유 메모리(Shared Memory)를 가질 수도 있는데, 이때 각 에이전트의 메모리 힙에는 자체 버전의 SharedArrayBuffer 객체를 갖고 있지만 버퍼로 표현되는 기본 메모리(underlying memory)는 공유하는 방식으로 공유 메모리가 구현된다. 다만 에이전트를 생성할 때 메모리를 공유하는 하나의 클러스터로 묶일 수 있는지에 대한 기준이 존재하는데, 자세한 내용은 여기서 확인할 수 있다.
스택과 실행 컨텍스트
이 부분은 우리가 익히 알고 있는 자바스크립트가 코드를 동기적으로 실행하는 과정에 대한 내용이다. 아래 그림과 같이 어떠한 함수가 실행될 때 해당 함수의 자체 변수 환경과 복귀 위치를 추적하기 위한 실행 컨텍스트(Execution Context)가 생성되고, 실행 컨텍스트(또는 스택 프레임)가 콜 스택(Call Stack)에 Push/Pop 되는 것을 반복하다가 스택이 비면 더 실행할 스크립트가 없다는 뜻이 된다. 전역 환경에서 실행되는 코드는 한 단위의 코드블록으로써 가상의 익명함수로 감싸져 있다고 생각하면 된다.
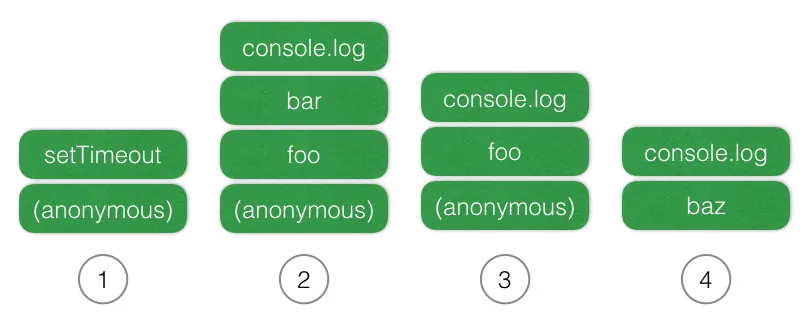
실행 컨텍스트에는 다음과 같은 내용들이 추적되고 있다.
- 코드 평가 상태
- 함수가 포함하고 있는 모듈, 스크립트, 함수, 그리고 현재 실행 중인 코드에 대한 Generator
- 현재 영역
- 지역 변수(var, let, const, function, class) 및 Private 식별자(ex. #foo), 바인딩된 this 값
여담이지만, 콜 스택에서 스택 프레임이 Pop되었다고 영원히 사라져버리는 것이 아니라 다시 스택으로 돌아가는 경우도 있는데, 제너레이터(Generator) 함수를 사용하는 경우이다.
function* gen() {
console.log(1);
yield;
console.log(2);
}
const g = gen(); // gen의 실행 컨텍스트가 g에 저장된다
g.next(); // gen의 실행 컨텍스트가 스택에 올라가고, yield 표현식이 나올 때까지 gen 내부 코드를 실행 (logs 1)
// yield 표현식을 만나면 실행 컨텍스트가 스택에서 제거된다
g.next(); // gen의 실행 컨텍스트가 다시 스택에 올라가고, yield 표현식에 의해 중단되었던 라인 이후의 코드를 실행 (logs 2)실행 컨텍스트와 연관 있는 또 하나의 개념이 클로저(Closure)다. 함수가 자신이 생성된 환경의 실행 컨텍스트의 변수 바인딩을 내부적으로 기억하여, 해당 실행 컨텍스트가 사라진 후에도 변수 값을 사용할 수 있는 개념이다. 클로저는 자바스크립트만의 독특한 현상은 아니고, 렉시컬 스코프를 가진 많은 언어들(Python, Ruby, Lua, Swift, Kotlin, Go 등)에서도 볼 수 있는 개념이다.
let f;
{
let x = 10;
f = () => x;
}
console.log(f()); // logs 10
이벤트 루프와 Run-to-completion
에이전트는 하나의 싱글 스레드로 동작하므로 한 번에 하나의 작업만 할 수 있다. 그렇지만 비동기 작업을 무한정 기다리며 이후 코드의 실행을 중단할 수는 없기 때문에(Never Blocking), 비동기 작업을 호스트 환경에 맡기고, 완료되었을 때 실행할 작업을 콜백(Callback)으로 정의하여 작업 큐(Job queue)에 대기하다가 이벤트 루프에 의해 콜 스택에 옮겨져 실행되게끔 동작한다.
이때 이벤트 루프는 콜 스택이 비어있을 때만 새로운 콜백을 실행하는데, 이는 자바스크립트의 Run-to-completion 모델과 연결된다. Run-to-completion은 현재 실행 중인 함수가 완전히 끝날 때까지는 다른 코드로 제어권이 넘어가지 않는다는 의미이다. 즉, 한 번 콜 스택에 올라간 함수는 중간에 멈추지 않고 끝까지 실행된다는 것이다.
C처럼 어떠한 스레드가 다른 스레드에 의해 런타임에 중지될 수 있는 언어와 달리, 자바스크립트는 Run-to-completion 모델로 실행되기 때문에 프로그램이 예측 가능하게끔 동작한다. 하지만 그렇기 때문에 하나의 작업이 너무 오래 걸리는 작업(Long task)이면, 끝날 때까지 웹에서는 유저 인터랙션이 중단되는 등의 문제가 발생할 수 있다. 그리고 개발자가 이러한 문제를 슬기롭게 해결하기 위해서는 이벤트 루프의 동작 과정에 대해 깊이 있게 이해할 필요가 있다.
Node.js 이벤트 루프의 구조와 작업 흐름
이제 이벤트 루프가 작업을 처리하는 과정을 구체적으로 살펴볼 텐데, 대표적인 두 호스트(브라우저, Node.js) 중에서 브라우저 대신 Node.js부터 살펴보는 이유는, Node.js 이벤트 루프의 동작 과정이 브라우저보다 받아들이기 쉽기 때문이다.
Node.js는 각자 다른 여러 개의 페이즈들과 큐들의 조합으로 이루어진 루프를 순환하며 작업들이 처리된다. 아래 그림을 보자.
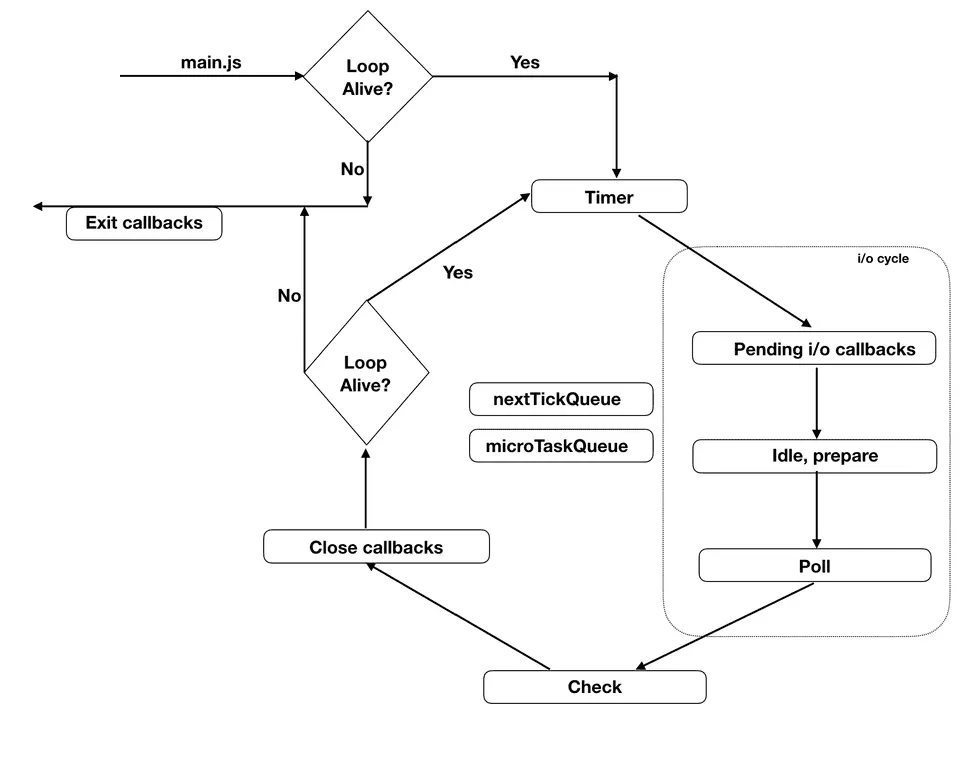
이 그림에 표기된 각각의 박스는 특정 작업을 수행하기 위한 페이즈들을 의미한다. 각 페이즈는 각자 하나의 큐(실제로는 큐가 아닐 수도 있다)를 가지고 있으며, 자바스크립트의 실행은 이 페이즈들 중 Idle, prepare 페이즈를 제외한 어느 단계에서나 할 수 있다. 또한, 그림에서 nextTickQueue와 microTaskQueue를 볼 수 있는데, 이 큐들에 들어있는 작업은 가장 높은 실행 우선 순위를 가지고 있으며, 후에 설명하겠지만 이 두 큐의 콜백들은 각 Tick(어떤 페이즈에서 다음 페이즈로 넘어가는 과정)마다 자신이 가지고 있는 콜백들을 최대한 빨리 실행해야 하는 역할을 맡고 있다.
각각의 페이즈가 어떤 작업을 수행하는지 알아보자.
Timer phase
이 페이즈가 가지고 있는 큐에는 setTimeout이나 setInterval 같은 타이머들의 콜백이 저장된다. 다만 타이머 콜백이 바로 큐에 들어가는 것은 아니고, 타이머들이 별도의 min-heap에 실행되어야 하는 순서대로(타이머 함수의 인자에 넣은 delta 값이 작은 순서대로) 저장되어 있다가, 이벤트 루프가 Timer phase에 진입했을 때, 저장된 타이머들을 하나씩 검사하면서 now - registeredTime === delta 같은 조건을 통해 타이머의 콜백을 실행할 시간이 되었는 지 검사하게 된다.
Timer phase는 큐가 빌 때까지 순서대로 실행하지만, 시스템의 실행 한도에도 영향을 받고 있어서, 실행되어야 하는 타이머가 아직 남아 있다고 하더라도 시스템 실행 한도에 도달한다면 바로 다음 페이즈로 넘어가게 된다. 이는 nextTickQueue와 microTaskQueue를 제외한 다른 페이즈들의 큐에도 적용되는 제약사항이다.
Pending i/o callback phase
이 단계에서는 이전 루프에서 이미 완료되어 “대기 중”으로 넘어온 I/O 콜백들을 처리한다. 대표적으로 에러 핸들러, 일부 네트워크·파일 작업의 후속 콜백이 pending_queue에 쌓여 있으며, 큐가 빌 때까지(또는 시스템 실행 한도에 도달할 때까지) 순서대로 실행한다.
Idle. prepare phase
이름은 Idle phase이지만 이 페이즈는 매 Tick마다 실행되며, 실제로는 다음 Poll phase로 진입하기 전·후에 내부 상태를 정리하거나 준비하는 용도로 쓰이는 Node.js 내부 관리용 훅에 가깝다.
Poll phase
이벤트 루프에서 가장 중요한 페이즈다. 파일 읽기 응답, 소켓 데이터 수신 등 “새로 들어온 I/O 이벤트”를 받아 해당 콜백을 실행한다. 동작은 다음과 같다.
watcher_queue에 작업이 있으면 큐가 빌 때까지(또는 실행 한도에 도달할 때까지) 콜백을 실행한다.watcher_queue가 비어 있으면Check phase에서 실행할setImmediate콜백이 있는지 확인한다. 없다면 등록된 타이머를 확인해보고 타이머 콜백을 실행해야 하는 시간이 될 때까지 Poll phase에서 대기한다. 이렇게 대기하는 이유는 불필요하게 이벤트 루프를 순환하지 않도록 하기 위함이다.
Check phase
setImmediate로 예약된 콜백들을 실행한다. 타이머처럼 시간 만료 검사 비용이 없고 Poll phase 직후에 바로 진입하기 때문에, I/O 콜백 내부에서 다음 페이즈에 곧바로 이어서 실행하고 싶은 작업을 정의할 때 유용하다. 콜백을 작업 큐의 앞 쪽에 밀어넣는 것이 아니라 setImmediate 만을 처리하기 위한 전용 페이즈와 큐가 존재하는 것이다.
Close callbacks phase
이 단계에서는 소켓 등 자원의 close/destroy 이벤트 콜백을 처리한다.
nextTickQueue, microTaskQueue
nextTickQueue는 process.nextTick() API의 콜백을 가지고 있으며, microTaskQueue는 Resolve된 프로미스(Promise)의 콜백을 가지고 있다. 이 두 큐는 기술적으로libUV 라이브러리에 포함된 것이 아니라 Node.js에 포함된 기술이며, 어떤 페이즈에서 다음 페이즈로 넘어가기 전에 큐의 콜백들을 모두(다른 페이즈들과 달리 실행 한도 없이) 실행한다. 그리고 nextTickQueue는 microTaskQueue보다 높은 우선 순위를 가지고 있다.
nextTickQueue에 담긴 작업은 실행 한도 없이 모두 수행되어야 하기 때문에, 해당 작업이 재귀 호출을 수행하는 경우 Node.js의 작업 프로세스를 Blocking할 수 있다는 점에 주의해야 한다.
libUV와 Thread-pool
Node.js의 비동기 I/O는 C로 작성된 라이브러리인 libuv가 처리한다. 이 라이브러리는 커널의 이벤트 기반 메커니즘을 추상화한 형태이기 때문에, OS 커널을 사용하여 처리할 수 있는 비동기 작업은 커널에게 넘기고, 작업들이 종료되어 OS 커널로부터 시스템 콜을 받으면 이벤트 루프에 콜백을 등록한다. 만약 파일 읽기/쓰기, DNS Lookup과 같이 OS 커널이 지원하지 않는 작업일 경우 별도의 스레드풀(Thread-pool)에 작업을 넘겨 처리한다.
setTimeout(fn, 0) vs setImmediate()
Timer phase는 내부적으로 타이머를 등록하고 시간을 비교하여 편차를 알아내는 과정 때문에 발생하는 지연과 불확실성을 내포하고 있다. 예를 들어 다음과 같은 코드에서 setTimeout이 먼저 출력된다는 보장은 없다.
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
});이유는 다음과 같다.
- 메모리에 타이머를 저장하는 과정에서 컴퓨터 성능이나 Node.js 외부 작업에 의해 딜레이가 발생할 수 있다.
setTimeout(fn, 0)은 실질적으로 0이 아니라 사실 1이다. 타이머의 딜레이를1ms보다 작거나2147483647ms보다 크게 설정하면 딜레이는 자동으로1로 세팅된다- Node.js가
Timer phase에 ‘진입하기 전에’ 변수now를 선언하고 그 변수now를 현재 시간으로 간주하기 때문에 해당 값은 약간의 노이즈가 껴 있고 정확한 계산이라고 하기 어렵다
setImmediate을 사용하면 타이머를 사용할 때처럼 딜레이의 시간이 지났는지 검사하는 로직이 필요없어지고, HTTP 요청 콜백과 같은 곳에서 사용되는 경우 Poll phase 직후에 수행되기 때문에 setTimeout 보다 빨리 실행된다고 할 수 있다.
setImmediate() vs process.nextTick()
이름만 보면 setImmediate 작업은 ‘즉시’ 실행될 것 같지만 실질적으로는 다음 페이즈 혹은 다음 이벤트 루프의 순회에서 Check phase에 진입해야 실행된다. 오히려 nextTick 작업이 현재 작업을 마치고 진짜로 ‘즉시’ 호출되도록 작동한다. 그래서 기능적으로는 오히려 이름이 서로 반대가 되는 게 어울린다 😅
브라우저 이벤트 루프의 구조와 작업 흐름
이제 브라우저 이벤트 루프를 살펴보자. 브라우저에서는 Node.js 환경과 달리 아래처럼 꽤나 다양한 일들을 처리해야 한다.
- HTML 문서에서 스크립트를 파싱해야 한다
- 중간중간 유저 인터랙션(클릭, input, 스크롤 등)이 발생한다
- 디스플레이 주사율 주기에 맞춰 Animation Callback을 실행해야 한다
- 렌더링이 필요할 때마다 렌더링 파이프라인을 실행해야 한다
브라우저에서 비동기 작업(타이머, AJAX 요청, 유저 이벤트 등)은 Web APIs가 처리한 후, 콜백을 적절한 작업 큐(매크로태스크 큐, 마이크로태스크 큐)에 등록하게 된다.
브라우저 이벤트 루프도, Node.js와 마찬가지로 정해진 순환 구조를 반복하는 건 마찬가지다. 아래 그림은 브라우저 이벤트 루프의 동작 과정을 수도코드로 나타낸 것이다.
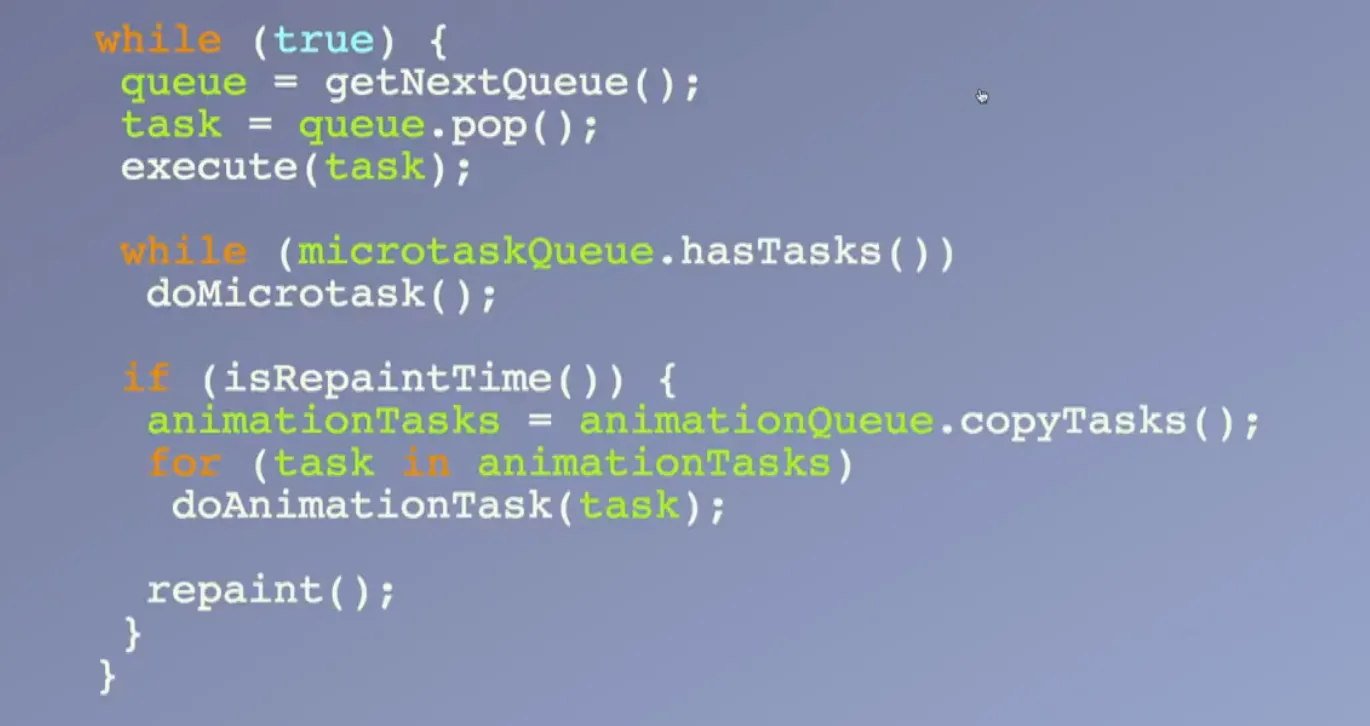
대표적으로 세 종류의 큐를 가지고 콜백들을 관리한다. 각각의 우선순위와 역할을 알아보자.
TaskQueue
매크로태스크 큐(macroTaskQueue)라고도 불리는 태스크 큐는 setTimeout, setInterval, DOM 이벤트 콜백 등이 들어가는 큐다. 메인 스레드에서 콜 스택이 ‘완전히 비워져야’ 이벤트 루프가 태스크 큐에서 콜백을 하나씩 가져와서 실행한다. setTimeout이 정확히 지정된 시간 후에 실행된다는 보장이 없는 것도 이 때문이다. 콜백 실행이 끝나고 나면 필요시 렌더링을 진행한 뒤 다시 콜백이 있는지 확인한다.
console.log('시작');
setTimeout(() => {
console.log('100ms 타이머');
}, 100);
// 5초 동안 메인 스레드를 바쁘게 만듦
const start = Date.now();
while (Date.now() - start < 5000) {
// 5초간 대기
}
console.log('끝');
// 실행 결과:
// 시작
// (약 5초 후) 끝
// (약 5초 후) 100ms 타이머 microTaskQueue
초기 자바스크립트에는 매크로태스크 큐만 존재했으나, ES6에서 Promise가 도입되고, DOM 변경을 감지하는 Mutation Observer 같은 기능들이 등장하면서 작업이 끝나자마자 바로 실행되어야 하는 작업들을 처리해야 할 필요가 생겼다. 예를 들어 Mutation Observer는 DOM이 변경되는 순간을 감지해야 하는데, 만약 콜백을 매크로태스크 큐에 넣으면 다음 작업으로 넘어가기 전에 렌더링이 먼저 일어날 수 있다.
그래서 도입된 것이 마이크로태스크 큐이다. 마이크로태스크 큐에는 Promise.then(), Promise.catch(), Promise.finally(), async/await, queueMicrotask() 등의 콜백들이 들어간다. 각 작업이 끝난 직후 브라우저 이벤트 루프는 마이크로태스크 큐를 전부 비우고, 필요시 렌더링한 후 다음 작업을 실행한다. 즉, 마이크로태스크 큐의 작업들은 콜 스택이 비워지고 렌더링하기 전에 반드시 실행되기 때문에 DOM 변경이나 Promise 콜백 등을 “지연 없이” 처리할 수 있는 것이다.
그리고 위에서 보았던 브라우저 이벤트 루프의 수도코드를 보면 while문을 돌며 마이크로태스크 큐가 완전히 비워질 때까지는 이벤트 루프의 다음 단계로 넘어가지 않는다는 것을 확인할 수 있다. 이는 Promise 체인이나 연속된 마이크로태스크들이 렌더링이나 다른 작업들보다 항상 우선하여 실행됨을 의미한다. 때문에 Node.js 이벤트 루프의 nextTickQueue에서 언급한 것처럼, 브라우저 이벤트 루프의 마이크로태스크 큐에서도 재귀적인 호출이 일어나거나 긴 작업을 수행하는 경우 브라우저 프로세스를 Blocking할 수 있다는 점에 주의해야 한다.
animationQueue
브라우저 환경은 렌더링 파이프라인이 포함되어 있다. 그래서 60Hz 주사율을 가진 디스플레이 기준으로 16.6ms 주기의 Repaint Time에 렌더링 작업을 진행해야 한다. 흔히 브라우저 주사율에 맞춘 부드러운 애니메이션을 제공하기 위해 사용하는 requestAnimationFrame 함수의 콜백이 그래서 DOM 렌더링이 필요한 시점에 실행되는 것이다.
requestAnimationFrame과 같은 함수의 콜백들이 animationQueue에 등록되면, 이벤트 루프는 매크로태스크 큐의 작업을 하나 완료했거나, 마이크로태스크 큐의 모든 작업을 완료한 다음 렌더링 타임이 된 경우 ‘해당 시점에 등록되어 있는’ animationQueue의 모든 콜백들을 처리하고 이후 렌더링 파이프라인을 진행한다.
여기서 눈여겨봐야 할 점은 microTaskQueue와 달리 animationQueue는 copyTasks()를 해서 ‘해당 시점에 등록된’ 콜백들만 처리한다는 것이다. 그 이유는 animationQueue에 등록된 콜백들은 개발자가 ‘의도된 애니메이션’을 DOM 렌더링 직전에 실행하기 위해 존재하기 때문이다. 아래 예시를 보자.
this.browser.classList.remove('slide');
this.browser.classList.add('slide');위 스크립트를 실행하면 브라우저는 slide 클래스가 지워졌다 다시 복구된다고 판단하여 실제 렌더링 시에는 어떠한 변화도 주지 않는다. 하지만 아래 예시를 보자.
requestAnimationFrame(() => {
this.browser.classList.remove('slide');
requestAnimationFrame(() => {
this.browser.classList.add('slide');
});
});위 경우는 어떨까? 첫 번째 requestAnimationFrame함수의 콜백이 Repaint time이 되어 animationQueue에서 실행될 때,slide 클래스가 일단 remove될 것이다. 그러나 직후에 requestAnimationFrame함수를 또 호출하며slide 클래스를 다시 add하는 콜백을 animationQueue에 등록했다. 그럼에도 불구하고 이 두 콜백(remove, add)들은 동일한 주기에 실행되지 않는다. 왜냐하면 위에서 서술했듯 animationQueue는 일단 ‘해당 시점에 등록된’ 콜백들만 처리하고, 처리 도중에 추가로 등록된 콜백은 다음 이벤트 루프 주기(tick)에서 실행하기 때문이다.
결과적으로 위 코드를 실행하면 개발자가 의도한 대로 slide 클래스가 remove될 때의 애니메이션과, 다시 add될 때의 애니메이션을 순서대로 모두 표시할 수 있게 되는 것이다.
그리고 이쯤 되면 왜 setTimeout 대신 requestAnimationFrame으로 애니메이션을 구현하는 것이 좋은지 알 수 있을 것이다. Node.js 이벤트 루프 설명때와 마찬가지로, setTimeout은 명시한 delay가 지난 뒤에 실행될거라는 보장이 없고, 타이머 동작의 특성상 발생하는 지연 때문에 콜백이 조금씩 밀리다 보면 일부 프레임이 건너뛰어지면서 애니메이션이 끊겨 보이게 된다. 즉, setTimeout을 사용하면 requestAnimationFrame 대비 화면 업데이트 주기와의 동기화 불일치가 발생할 확률이 높다는 것이다. 또한 requestAnimationFrame은 백그라운드 탭에서 자동으로 일시정지되어 시스템 리소스를 절약하기도 한다.
수도코드를 보면 macroTask가 먼저 처리되는 것 아닌가?
수도코드를 보면 왜 macroTask가 microTask보다 먼저 처리되는지 의아해할 수 있다. 이에 대해 알기 위해서는 이벤트 루프의 tick에 대해 이해해야 한다. 브라우저에서 이벤트 루프의 한 tick이란 macroTaskQueue 실행 → microTaskQueue 실행 → animationFrameQueue 실행 → Repaint하는 하나의 동작 주기를 뜻한다.
자바스크립트에서 setTimeout을 Promise의 resolve 함수보다 먼저 실행시켜도, 실제로 더 늦게 실행되는 것처럼 보이는 이유는, setTimeout의 콜백 함수가 다음 tick에서 실행되기 때문이다.
브라우저에서 ‘긴 작업’을 최적화하는 방법
이상적으로는 60Hz 주사율 디스플레이 기준으로, 메인 스레드에서 3가지 큐(macroTaskQueue, microTaskQueue, animationTaskQueue)의 작업들을 완료하고 렌더링 파이프라인을 16.6ms 내에 수행해내야, 컴포지터가 제 시간에 frame drop 없이 화면을 표시할 수 있다. 하지만, 긴 작업(Long task)은 자바스크립트의 Run-to-completion 모델에 따라 브라우저의 메인 스레드를 차단하여, 상호작용을 시도했을 때 사용자 인터페이스가 응답하지 않는 것처럼 느껴지게 만들 수 있다.
그렇다면 어떻게 해야 메인 스레드가 너무 오랫동안 차단되는 것을 방지하여 높은 응답성을 제공할 수 있을까? 그 방법은 긴 작업을 여러 개의 작은 작업으로 분할하는 것이다.
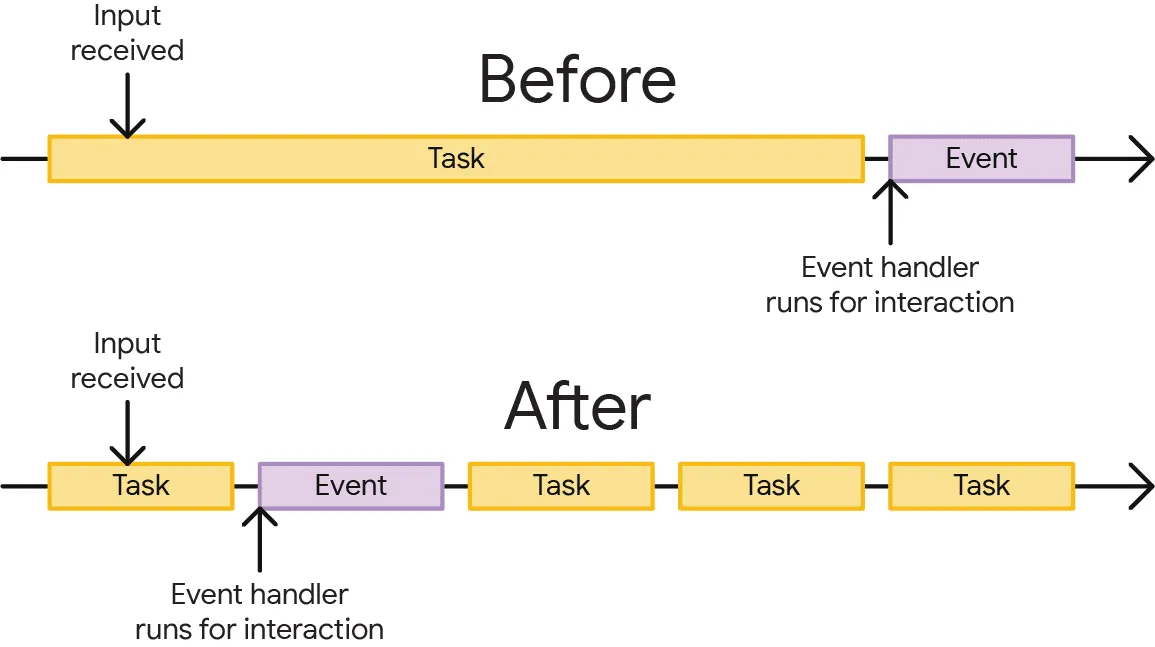
작업이 분할되면 브라우저가 사용자 상호작용과 같이 우선순위가 높은 작업에 훨씬 더 빨리 응답할 수 있다. 그 후, 나머지 작업들이 완료될 때까지 실행되어 처음에 대기열에 추가했던 작업이 완료되도록 보장할 수 있다.
작업은 어떻게 분할해야 할까? 일단 하나의 함수로 작성했던 긴 작업을 아래와 같이 여러 개의 작은 함수들로 분할할 수 있겠다.
function saveSettings () {
validateForm();
showSpinner();
saveToDatabase();
updateUI();
sendAnalytics();
}기존보다 꽤 괜찮은 설계이긴 하지만, 결국 saveSettings 함수를 자바스크립트가 별도의 5개 작업으로 실행해주지는 않는다. 여전히 하나의 작업으로 실행된다.

중요한 사용자 인터랙션과 UI 응답이 우선순위가 낮은 작업보다 먼저 실행되도록 하려면, 작업을 잠시 중단하여 브라우저가 더 중요한 작업을 실행할 수 있는 기회를 제공함으로써 ”메인 스레드에 양보(yield)”해야 한다. 그러니까, 이벤트 루프의 관점에서 보면, 작업을 분할하여 다음 tick에서 실행될 수 있도록 만들어야 한다는 것이다.
메인 스레드에게 양보(yield)하기
메인 스레드에 양보하는 널리 알려진 한 가지 방법으로 setTimeout(fn, 0)이 있다. 이렇게 하면 타이머를 0ms로 지정하더라도 콜백이 매크로태스크에 등록되고 다음 tick에서 실행된다.
function saveSettings () {
// 유저에게 보여지는 UI 관련 작업들을 먼저 처리한다
validateForm();
showSpinner();
updateUI();
// 백그라운드에서 실행되는(UI와 관련없는) 작업들을 미루고 메인스레드에 양보한다
setTimeout(() => {
saveToDatabase();
sendAnalytics();
}, 0);
}그러나 setTimeout의 문제는, 5번 이상 반복 실행될 경우 지연 실행 시간을 0ms로 설정해도 브라우저 스펙에 의해 최소 4ms 지연시간이 추가된다는 점이다. 또한 setTimeout으로 양보하는 경우 해당 작업이 태스크 큐의 끝에 추가되기 때문에, 태스크 큐에 대기 중인 다른 작업이 있는 경우 해당 작업들이 모두 처리되고 나서야 지연된 작업이 실행된다는 것도 단점이다.
가장 좋은 방법은 브라우저 API인 scheduler.yield()를 사용하는 것이다. 해당 메소드는 실행되자마자 메인스레드를 양보하고 Promise를 반환하기 때문에, scheduler.yield() 이후의 코드는 마이크로태스크 큐에 들어가서 실행되게 된다.
async function saveSettings () {
// 유저에게 보여지는 UI 관련 작업들을 먼저 처리한다
validateForm();
showSpinner();
updateUI();
// 메인 스레드에 양보
await scheduler.yield()
// 백그라운드에서 실행되는(UI와 관련없는) 작업들이 continous하게 처리된다
saveToDatabase();
sendAnalytics();
}
scheduler.yield() 의 또 다른 장점은, continous한 작업을 보장한다는 점이다. 매크로태스크에 대기중인 다른 작업들이 있을 경우 yield한 작업들의 실행이 밀릴 수 있는 setTimeout과 달리(한 tick에 task가 하나 실행되므로 지연 발생), scheduler.yield()로 yield한 작업들은 마이크로태스크 큐에 등록되므로, 메인 스레드에 양보한 작업들이 끝나면 이벤트 루프가 마이크로태스크 큐를 한 tick에 모두 비우면서 곧바로 실행되기 때문이다. 아래 그림은 작업을 setTimeout으로 양보했을 때와 scheduler.yield()로 양보했을 때의 작업 지속성 차이를 보여준다.
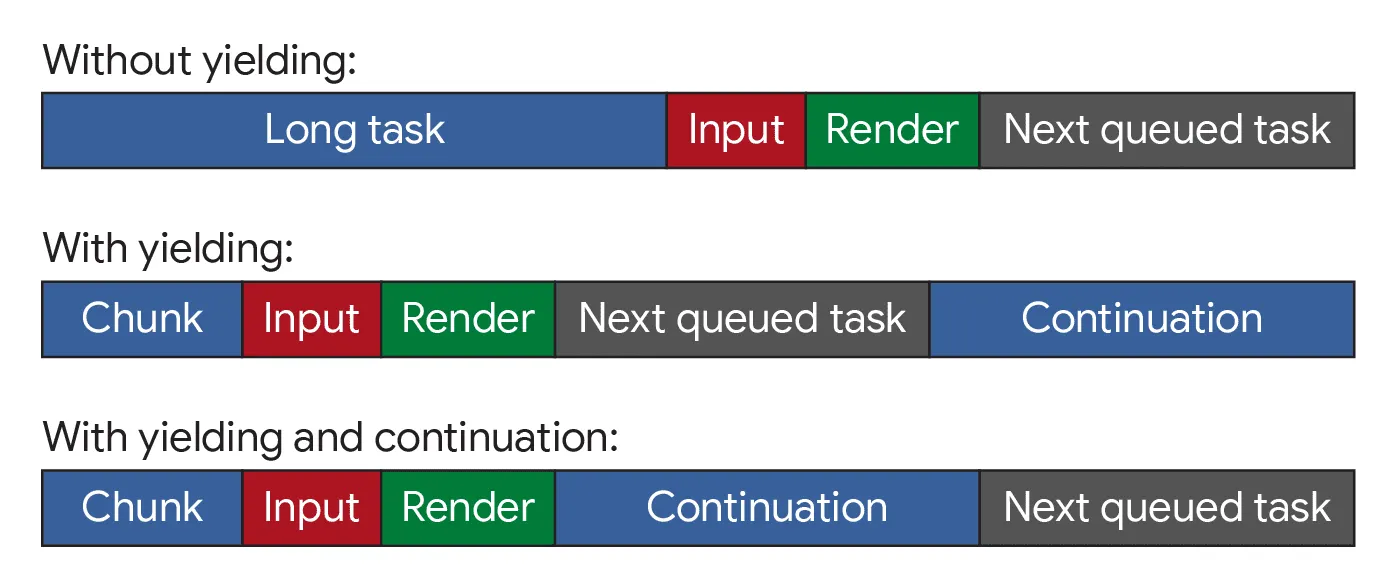
scheduler.yield()는 현재 Safari에서 지원이 안 되기 때문에 polyfill이 필요하다. 크롬 팀에서 제공하는 scheduler-polyfill을 사용하거나, 아래와 같이 setTimeout()을 Promise에 감싼 덜 정교한 버전의 코드를 작성할 수도 있다. 물론 이 경우 continuation이 보장되지는 않는다.
function yieldToMain () {
if (globalThis.scheduler?.yield) {
return scheduler.yield();
}
// Fall back to yielding with setTimeout.
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}아니면 postMessage()를 활용하는 방법도 있다. 원래는 서로 다른 에이전트 간 통신(ex. 탭 간 소통)을 위해 있는 함수지만, 매크로태스크 큐를 통해 실행되고 setTimeout()처럼 반복 실행됐을 때 디폴트로 추가되는 delay가 없기 때문에 보다 괜찮은 옵션이다.
function yieldToMain() {
if (globalThis.scheduler?.yield) {
return globalThis.scheduler.yield();
}
return new Promise((resolve) => {
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = () => {
resolve();
};
port.postMessage(null);
});
}여담으로, 작업을 분할하기 위해 requestAnimationFrame(RAF)을 활용하는 방법에 대해 알고 있을지도 모른다. 하지만 이것은 엄밀하게는 메인스레드에 yield하는 방법은 아니다. 왜냐하면 RAF 콜백 함수는 이벤트 루프의 한 tick 내에서 실행되기 때문이다. 즉, setTimeout처럼 한 번의 Repaint 작업 이후 다음 tick에서 실행되는 것이 아니라, 콜백 함수들이 모두 실행되고 그 다음에 Repaint가 실행되는 것이다. 따라서 RAF으로 메인스레드에 양보하려면 RAF 콜백 함수 안에 RAF을 넣어야 한다(콜백 함수 안의 RAF 콜백은 다음 tick에 실행되기 때문이다). 그래서 UI를 반복적으로 주사율과 동기화하며 업데이트하는 작업이라면 RAF가 좋은 옵션이지만, 양보가 필요한 작업이 UI를 업데이트하는 작업이 아닌 경우에는 scheduler.yield() 를 통해 다음 tick에 실행되도록 하는 것이 좋을 것이다.
정리해 보면
- 자바스크립트가 싱글 스레드로 동작하는 이유는
DOM조작을 위해 설계된 만큼 경쟁 상태와 UI 불일치를 피하고, DOM의 예측 가능성을 높이기 위해서라고 볼 수 있다. - 자바스크립트가 싱글 스레드임에도 불구하고 동시성(Concurrency)을 지원할 수 있는 이유는 자바스크립트의 실행이 싱글 스레드인 자바스크립트 엔진과 멀티 스레드인 호스트 환경(브라우저, Node.js 시스템의 libuv 등)의 협력으로 이루어지기 때문이다.
- 자바스크립트 엔진은 단순히 코드의 실행만 담당하고, 실제 비동기 작업을 수행하는 역할은 호스트 환경의 다른 스레드에서 담당한다. 그리고 이러한 비동기 멀티 스레드 작업들과 싱글 스레드인 자바스크립트 엔진 사이의 상호작용을 담당하는 것이 바로 ‘이벤트 루프’다.
- 이벤트 루프는 메인 스레드가 콜 스택과 큐를 번갈아 확인하면서 콜백을 실행하는 반복 사이클이 구현된 개념적인 모델일 뿐이다. 그 사이클의 세부적인 정의와 구현이 호스트마다 다를 뿐이지, 이벤트 루프가 엔진 밖 호스트에서 자체적인 메모리나 스레드를 갖고 존재하는 어떠한 ‘실체’인 것은 아니다.
- 자바스크립트를 싱글 스레드로 실행하는 논리적 실행 단위를 에이전트(Agent)라고 하며, 에이전트는 자체 메모리 힙, 콜 스택, 작업 큐(이벤트 루프), 1개 이상의 영역(Realm)을 갖는다
- 이벤트 루프가 콜 스택이 비어있을 때만 새로운 콜백을 실행하는 것은 자바스크립트의
Run-to-completion모델과 관련있다. 결국엔 이벤트 루프가 비동기 작업을 처리하는 것도 싱글 스레드로 처리하는 것이다. - 자바스크립트의
Run-to-completion모델은 프로그램을 예측 가능하도록 만들어주지만, 너무 오래 걸리는 작업(Long task)을 실행하면 작업이 끝날 때까지 메인 스레드를 차단하여 웹에서 반응성 문제가 발생할 수 있다. 개발자가 이러한 문제를 슬기롭게 해결하기 위해서는 이벤트 루프의 동작 과정에 대해 깊이 있게 이해할 필요가 있다. - 긴 작업을 실행하는 도중에 메인 스레드에 양보(yield)하여 메인 스레드가 너무 오랫동안 차단되지 않도록 하는 좋은 방법 중 하나는
scheduler.yield()를 사용하는 것이다. 해당 메소드를 사용하면 실행되자마자 메인 스레드를 양보하고, 양보한 작업들이 끝나면 이벤트 루프가 마이크로태스크 큐를 한 tick에 모두 비우면서scheduler.yield()이후의 코드들이 지속성 있게(continous) 실행되기 때문이다.
참고 자료
자바스크립트와 이벤트 루프
자바스크립트는 싱글 스레드 언어인데 비동기 처리는 어떻게 가능한가요?
Javascript Execution Model - MDN
로우 레벨로 살펴보는 Node.js 이벤트 루프
Furthur Adventures of the Event Loop - Erin Zimmer - JSConf
Optimizing long tasks - web.dev